
Insights
The idea of characterizing the statistical variability of the traits of the human face dates back to the early ’80s. This idea was extended further in the work of Blanz and Vetter that proposed to construct a 3D morphable model (3DMM) from a set of example 3D face scans.
Similarly to the 2D case, the idea here is to capture the 3D face variability in the training data using an average model and a set of deformation component. The statistical model is then capable of generating new face instances with plausible shape and appearance.
In order to guarantee the 3DMM capability of generalizing to new unseen identities, the training set should include the necessary variability in terms of gender, age and ethnicity. Furthermore, including in the training set scans with facial expressions is also required to enable the 3DMM to generalize to expressive data.
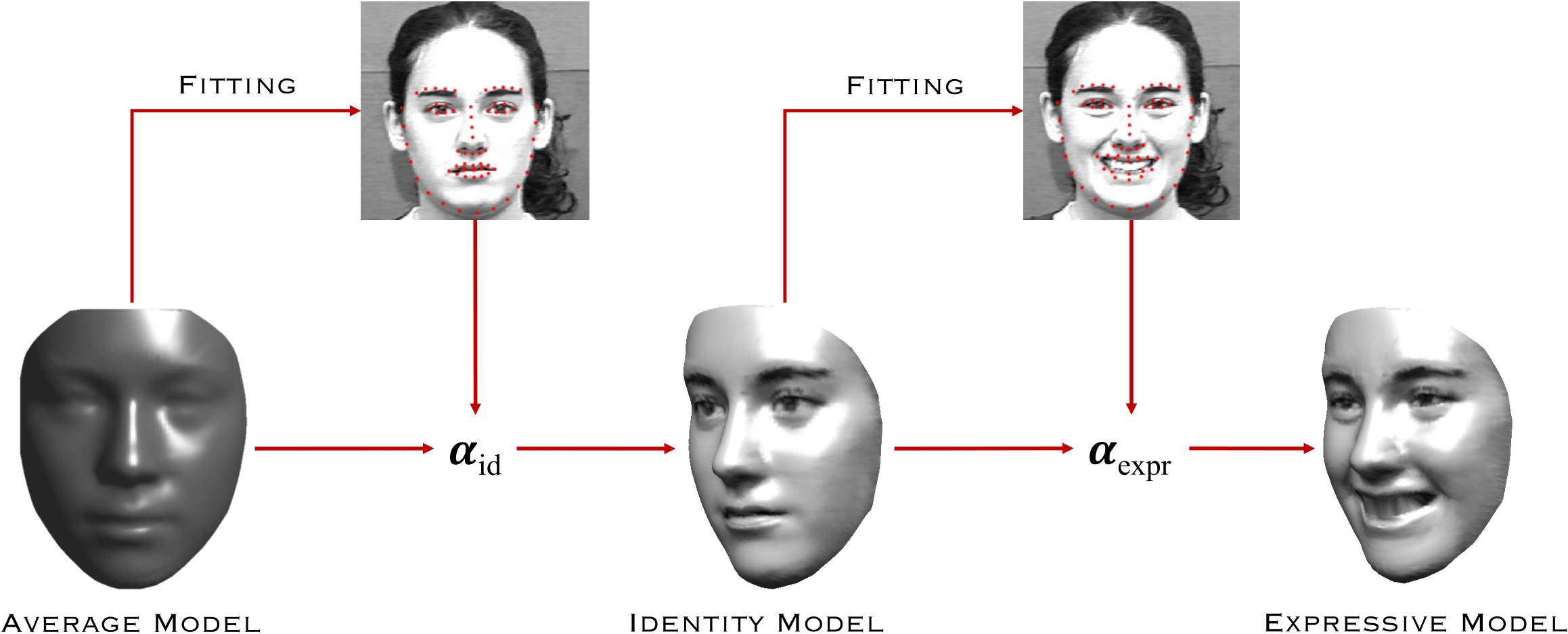
Given a face framed in an image, its 3D pose can be estimated by establishing a correspondence between a set of facial landmarks detected both in 2D and 3D. Once this correspondence is established and the pose is obtained, the average model is deformed in order to minimize the difference between the 2D and projected 3D landmarks locations. The statistics of the faces extracted from the train set of 3D scans ensures that the deformations involve larger areas of the 3D model.
The coefficients of the model that produce specific deformations can be learned and categorized so as to arbitrarily generate new models. In particular we devised a procedure to learn expression-specific sets of deformation coefficients. These can be subsequently applied to render expressive face images given its neutral counterpart.