Insights
Person identity recognition by the analysis of 3D face scans is attracting an increasing interest, with several challenging issues successfully investigated, such as 3D face recognition in the presence of non-neutral facial expressions, occlusions, and missing data.
Existing solutions have been evaluated on consolidated benchmark datasets, which provide a reasonable coverage of the different traits of the human face, including variations in terms of gender, age, ethnicity, and expressions, occlusions due to hair or external accessories, missing parts caused by pose changes. The resolution of 3D face scans can vary across different datasets, but given a dataset it is typically the same for all the scans. Therefore, the difficulties posed by considering 3D face scans with different resolution, and the impact of this variability on the recognition accuracy have not been explicitly addressed in the past. Nevertheless, there is an increasing interest for methods capable of performing recognition across scans acquired with different resolutions. This is motivated by the availability of a new generation of low-cost, low-resolution 3D dynamic scanning devices, such as Microsoft Kinect or Asus Xtion PRO LIVE. These devices are capable of a combined color-depth (RGB-D) acquisition at about 30fps, with an optimal working distance from the sensor ranging from 40cm up to 1.5m. The spatial resolution of such devices is lower than that of high-resolution 3D scanners, but these latter are also costly, bulky and highly demanding for computational resources. Based on the opposite characteristics evidenced by 3D dynamic low-resolution and 3D high-resolution scanners, new applicative scenarios can be devised, where high-resolution scans are likely to be part of gallery acquisitions, whereas probes are acquired with 3D dynamic cameras, resulting in lower resolution models. In this context, reconstructing a higher-resolution model out of a sequence of low-resolution depth frames is a plausible way to bridge the gap between low- and high-resolution acquisitions. This could open the way to more versatile 3D face recognition methods deployable in contexts where the acquisition of high resolution 3D scans is not convenient or even impossible.
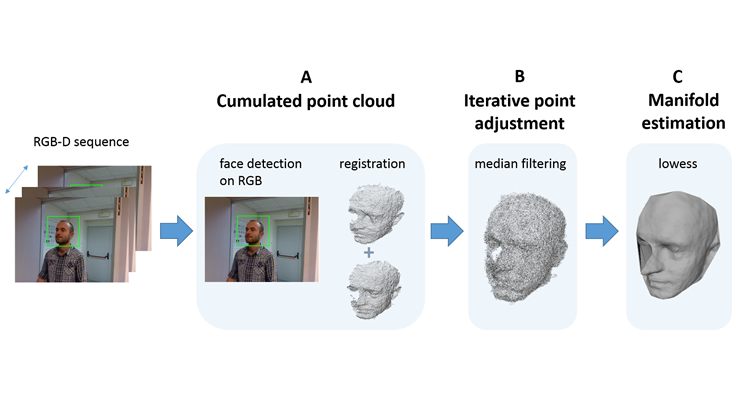
Based on these premises, in this research we defined an approach to reconstruct a higher-resolution face model from a sequence of low-resolution depth frames. Differently from previous solutions, that require user cooperation we enable the extraction of the 3D facial model of a person that just passes in front of the camera. In the proposed approach, first the face is automatically detected and cropped in each depth frame of a sequence, and the extracted 3D face data are aligned with each other, so as to build a cumulated face model. To perform non-rigid registration of point sets and account for deformation of the face during the acquisition process, the Coherent Point Drift (CPD) method is used. Then, an initial denoising operation is performed, which is based on the anisotropic nature of the error distribution with respect to the viewing direction of the acquired frames. Finally, a manifold estimation approach based on the lowess non-parametric regression method is used to approximate the face surface from the cumulated face model and remove outliers from the data. The approach has been evaluated in terms of accuracy of face reconstruction and face recognition on an the Extebded Florence Superface dataset, which includes depth sequences capturing the enrolled persons in cooperative as well as non-cooperative contexts, and high-resolution face scans acquired with a 3dMD scanner.