
Insights
At the basis of the work there is the Continuous Bag Of Word (CBOW) model from word2vec. In word2vec each word is mapped to a unique vector represented by a column in a word matrix W of Q length. Every column is indexed by a correspondent index from a dictionary VT. Given a sequence of words w1, w2, …, wK, the CBOW model aims at maximizing the average log probability of predicting the central word wt given the context represented by its M-window of words.
The output of the model is thus a word in the dictionary, more precisely the word is the one that, with higher probability, is considered to be more fitting for the provided input context. After training the method provides a mapping of each word in the dictionary to a point in a Q-dimensional continuous space. In the aforementioned space words are laid out in a way that semantic and syntactic relations are maintained, thus words that share something in common (as flower names, colors, animals or even verb forms) are put together.
The proposed model is an extension of CBOW specialized on the task of sentiment classification and a sample of the semantic-sentimental space can be seen in Figure 1.
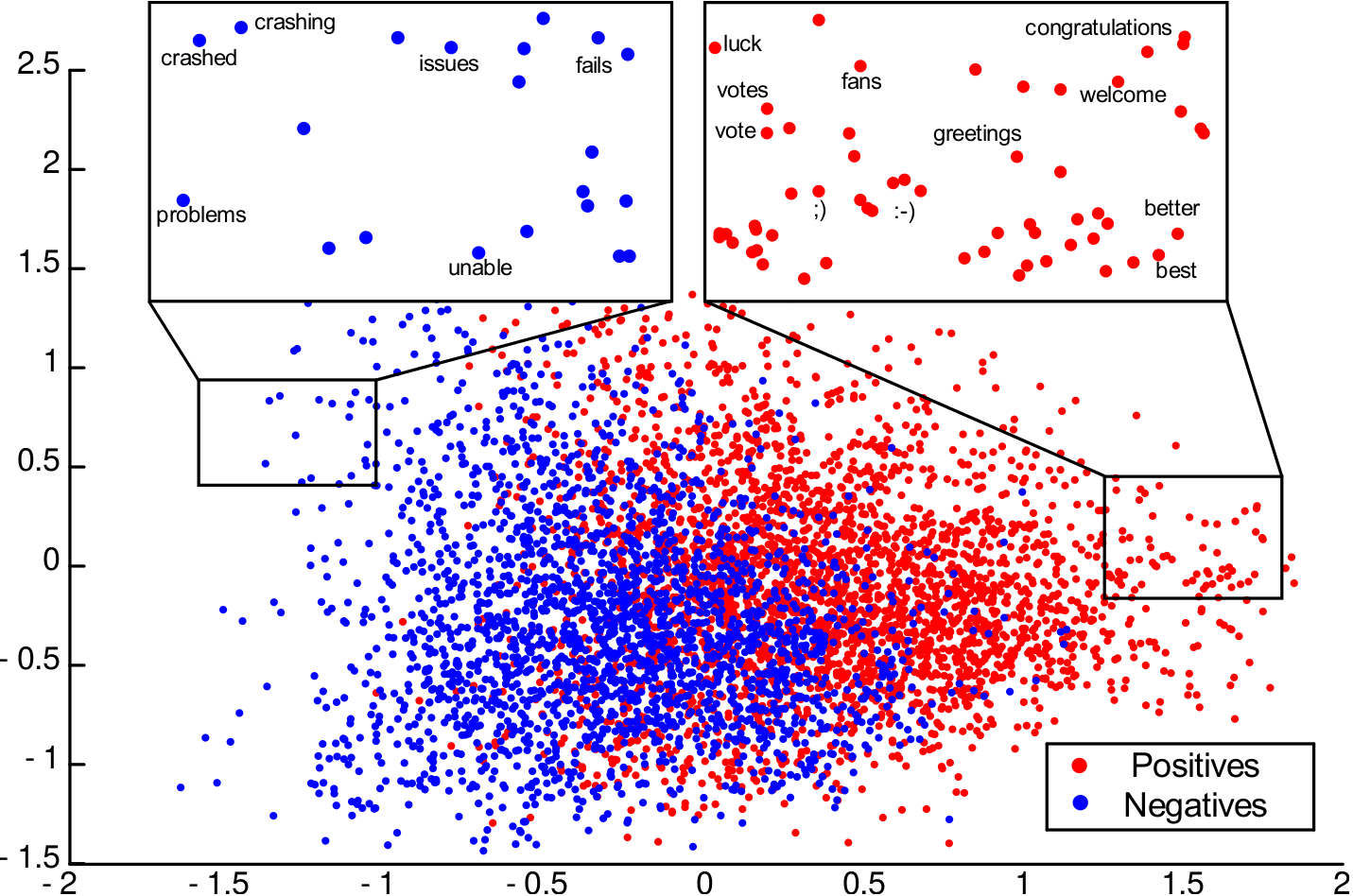
An important difference from approaches that directly use a CBOW representation is that the model learns representation and classification concurrently. Given a corpus of tweets X where each tweet is a sequence of words w1, w2, …, wK, we aim at classifying tweets as positive or negative, and learn word vectors W ∈ RQ×|VT| with properties related to the sentiment carried by words, while retaining semantic representation.
Semantic representation can be well-represented by a CBOW model, while sentiment polarity has limited presence or is lacking.
Note that polarity supervision is limited and possibly weak, thus a robust semi-supervised setting is preferred: on the one hand, a model of sentiment polarity can use the limited supervision available, on the other hand the ability to exploit a large corpus of unsupervised text, like CBOW, can help the model to classify previously unseen text.
This is explicitly accounted in the model by considering two different components:
- Sentiment Component: a feature learning task on words is consider by classifying sentiment polarity of a tweet. A tweet is represented as a set of M-window of words that is denoted as G. Each window G is represented as a sum of their associated word vectors Wi, and a polarity classifier based on logistic regression (LR) is applied accordingly.
A binary cross entropy is applied as loss function for every window G, and this is applied for every tweet T labeled with yT in the training set and results in a logistic regression cost evaluated over every window of every tweet.
- Semantic Component: semantics is explicitly represented by adding a task similar to negative sampling. The idea is that a CBOW model may also act as a regularizer and provide an additional semantic knowledge of word context. Given a window G a classifier has to predict if a word wl fits in it or not. This is the core of negative sampling: the set of presented samples F always contains the correct word wt for the considered context and K−1 random sampled wrong words from VT.
It is indeed a sampling as K < |VT|−1, that is the number of the remaining wrong words. Note that differently from the previous task, this is unsupervised, not requiring labeled data; moreover tweets can belong to a different corpus than that used in the previous component. This allows to perform learning on additional unlabeled corpora, to enhance word knowledge beyond that of labeled training words.
Finally, concurrent learning is obtained by forging a total cost, defined by the sum of the two parts, opportunely weighted by a λ ∈ [0, 1], and minimized with SGD. The CBOW-LR model can be extended in the CBOW-DA-LR model, shown in Figure 3, to account for visual information, such as that of images associated to tweets or status messages. To fit with the CBOW representation, the methods exploits the images by using a representation similar to the one used for the textual information, i.e. a representation obtained from the whole training set by means of a neural network.

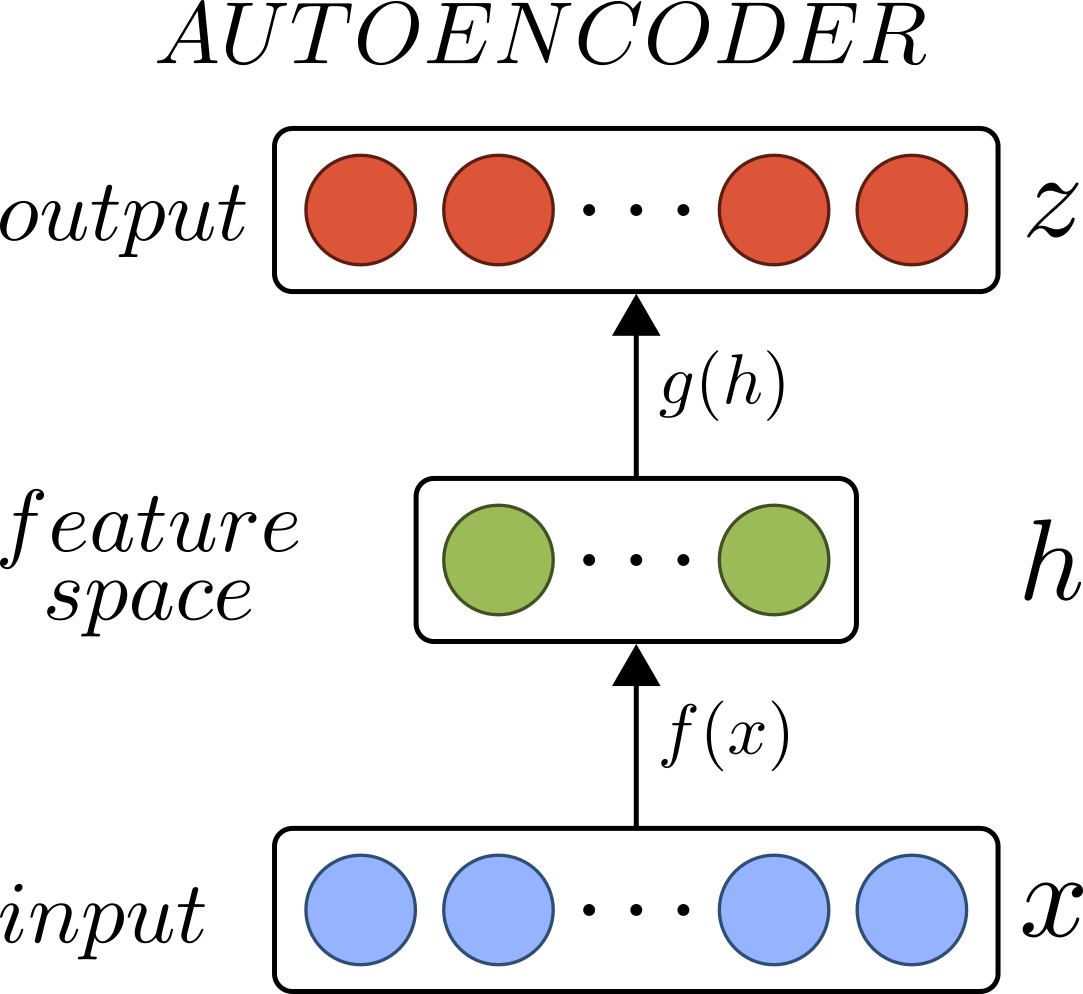
Moreover, likewise for the text, unsupervised learning can be performed. For these reasons a single-layer Denoising Autoencoder (DA), the model of which is shown in Figure 2, is chosen to extend the network and its middle level representation is taken as the image descriptor.
As for the textual version, the inclusion of this additional task allows the method to concurrently learn a textual representation and a classifier on text polarity and its associated image.

