
Insights
The exponential growth of media sharing websites, such as Flickr or Picasa, and social networks such as Facebook, has led to the availability of large collections of images tagged with human-provided labels. These tags reflect the image content and can thus be exploited as a loose form of labels and context. Several researchers have explored ways to use images with associated labels as a source to build classifiers or to transfer their tags to similar images.
Automatic image annotation is therefore a very active subject of research since we can clearly increase performance of search and indexing over image collections that are machine enriched with a set of meaningful labels. In this work we tackle the problem of assigning a finite number of relevant labels (or tags) to an image, given the image appearance and some prior knowledge on the joint distribution of visual features and tags based on some weakly and noisy annotated data.

Nearest-neighbors retrieved by baseline method.

Nearest-neighbors retrieved by KCCA method.
The main shortcomings of previous works in the field are twofold. The first is the well-known semantic gap problem, which points to the fact that it is hard to extract semantically meaningful entities using just low level visual features. The second shortcoming arises from the fact that many parametric models, previously presented in the literature, are not rich enough to accurately capture the intricate dependencies between image content and annotations.
Recently, nearest-neighbor based methods have attracted much attention since they have been found to be quite successful for tag prediction . This is mainly due to their flexibility and capacity to adapt to the patterns in the data as more training data is available. The base ingredient for a vote based tagging algorithm is of course the source of votes:~the set of K nearest neighbors. In challenging real world data it is often the case that the vote casting neighbors do not contain enough statistics to obtain reliable predictions. This is mainly due to the fact that certain tags are much more frequent than others and can cancel out less frequent but relevant tags. It is obvious that all voting schemes can benefit from a better set of neighbors. We believe that the main bottleneck in obtaining such ideal neighbors set is the semantic gap. We address this problem using a cross-modal approach to learn a representation that maximizes the correlation between visual features and tags in a common semantic subspace.
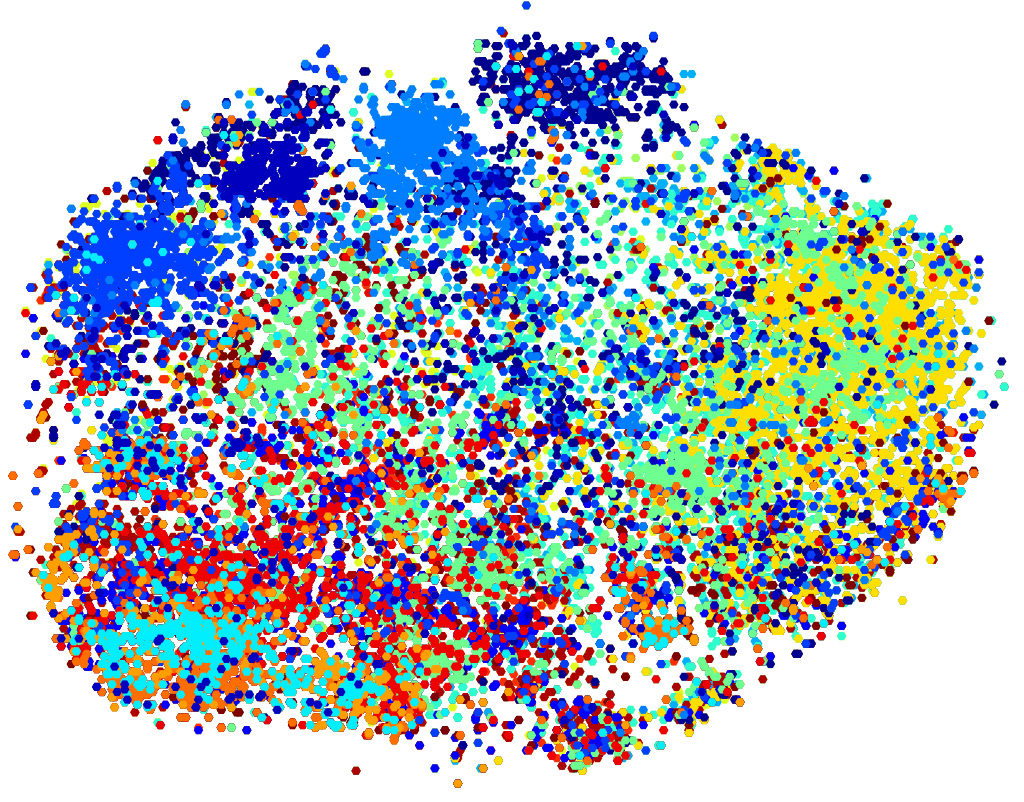
T-SNE plot of FC7 baseline features, each color represent a label.
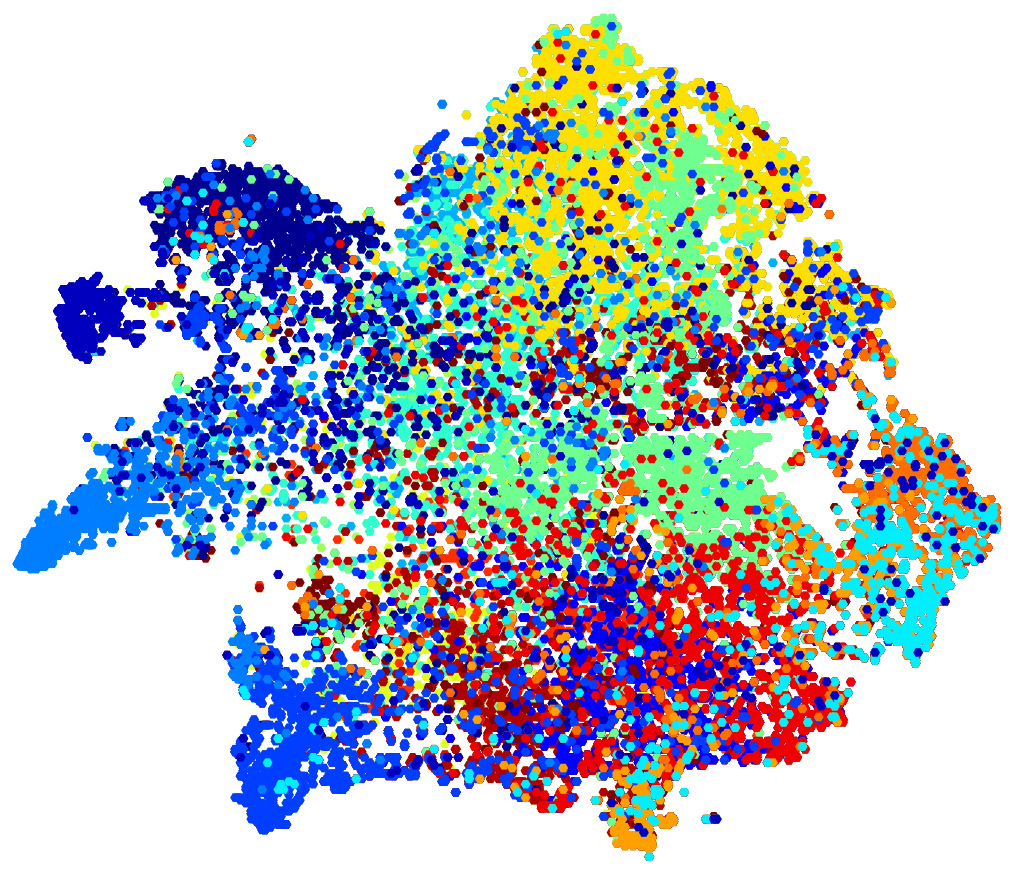
T-SNE plot of learned KCCA features, each color represent a label.
We compare for the same query, a flower close-up, the first thirty-five most similar examples provided by the visual features and by our representation. The first thing to notice is the large visual and semantic difference between the sets of retrieved neighbors by the two approaches. Note also that some flower pictures, which we highlight with a dashed red rectangle, were not tagged as such. Second, note how the result presented in Figure 1b have more and better ranked flower images than the one in Figure 1a . Indeed with the result set in Figure 1a it is not possible to obtain a sufficient amount of meaningful neighbors and the correct tag flower is canceled by others such as dog or people.
In this paper we present a cross-media approach that relies on Kernel Canonical Correlation Analysis (KCCA) to connect visual and textual modalities through a common latent meaning space (called semantic space). Visual features and labels are mapped to this space using feature similarities that are observable inside the respective domains. If mappings are close in this semantic space, the images are likely to be instances of the same underlying semantic concept. The learned mapping is then used to annotate new images using a nearest-neighbor voting approach. We present several experiments using different voting schemes. First, a simple NN voting similar to the seminal work of Makadia and second three advanced NN models such as TagRelevance, TagProp and 2PKNN.
PUBLICATIONS:
- L. Ballan, T. Uricchio, L. Seidenari, and A. Del Bimbo, “A Cross-media Model for Automatic Image Annotation,” in Proc. of ICMR, Glasgow, UK, 2014.
- A Data-Driven Approach for Tag Refinement and Localization in Web Videos
Lamberto Ballan, Marco Bertini, Giuseppe Serra, Alberto Del Bimbo
Computer Vision and Image Understanding (CVIU), Volume 140, page 58–67 – 2015. - Data-driven approaches for social image and video tagging
Lamberto Ballan, Marco Bertini, Tiberio Uricchio, Alberto Del Bimbo
Multimedia Tools and Applications, Volume 74, Number 4, page 1380–7501 – 2015. - Fisher Encoded Convolutional Bag-of-Windows for Efficient Image Retrieval and Social Image Tagging
Tiberio Uricchio, Marco Bertini, Lorenzo Seidenari, Alberto Del Bimbo
Proc. of ICCV Int’l Workshop on Web-scale Vision and Social Media – 2015. - Image Tag Assignment, Refinement and Retrieval
Xirong Li, Tiberio Uricchio, Lamberto Ballan, Marco Bertini, Cees Snoek, Alberto Del Bimbo
Proc. of ACM International Conference on Multimedia (MM) – Tutorial – 2015. - Love Thy Neighbors: Image Annotation by Exploiting Image Metadata
Justin Johnson, Lamberto Ballan, Li Fei-Fei
Proc. of IEEE International Conference on Computer Vision (ICCV) – 2015. - A Cross-media Model for Automatic Image Annotation
Lamberto Ballan, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo
Proc. of ACM International Conference on Multimedia Retrieval (ICMR) – Apr 2014. - An evaluation of nearest-neighbor methods for tag refinement
Tiberio Uricchio, Lamberto Ballan, Marco Bertini, Alberto Del Bimbo
Proc. of IEEE International Conference on Multimedia & Expo (ICME) – jul 2013. - Socializing the Semantic Gap: A Comparative Survey on Image Tag Assignment, Refinement and Retrieval”, X. Li et al., arXiv:1503.08248, 2015.