Insights
In the last decade users of social networks such as Flickr and Facebook have uploaded tens of billions of photos, often adding accompanying metadata by tagging and by providing a short description.
Inevitably, in the huge quantity of available media, some of these images are going to become very popular, while others are going to be totally unnoticed and end up in oblivion. Often, media may be popular because it conveys sentiments or it has a rich meaning in the social context it is put.
In this paper, we address the problem of predicting the popularity of an image posted in a social network, considering different scenarios that are typical of different situations.
The main contributions of this paper are:
- we propose to employ state-of-the-art visual sentiment features to perform image popularity prediction;
- we propose three new textual features based on a knowledge base, to better model the semantic description of an image, in addition to the social context features already proposed in literature;
- we show qualitative results of which sentiments seem to be related to a good or poor popularity.
Our proposed method is based on two hypotheses: i) the popularity of an image can be fueled by the inherent visual sentiments conveyed; ii) semantic descriptions of an image is also important for its popularity, since it makes it easier to be found or looked at.
We trained a Support Vector Regression using the following classes of features:
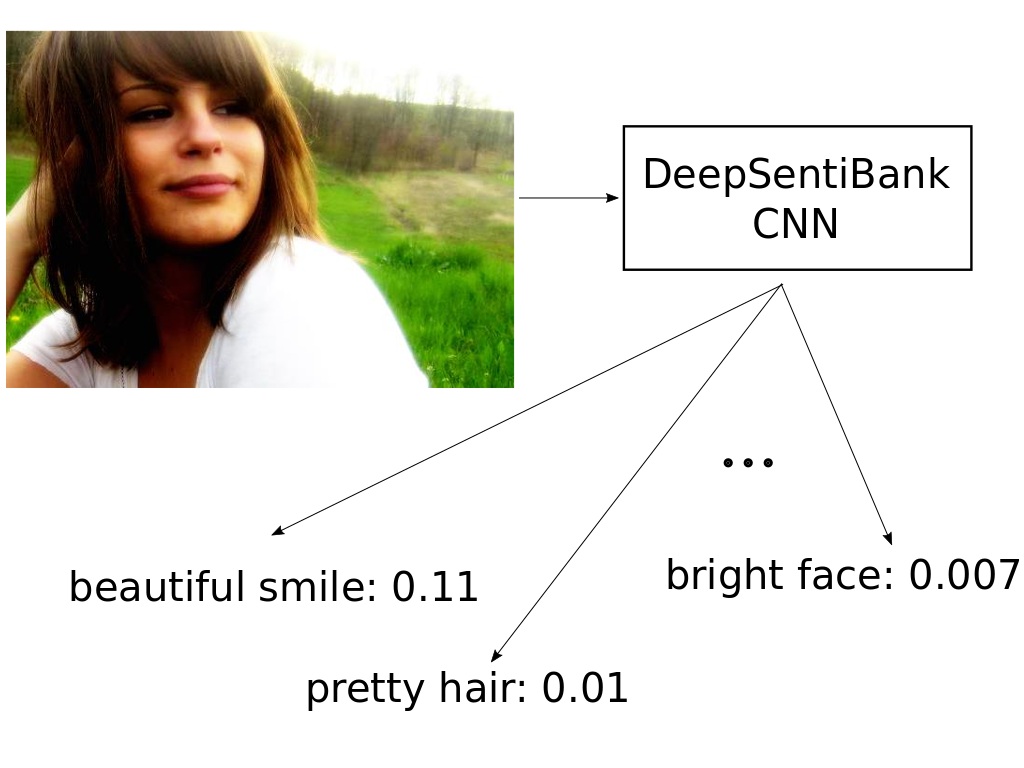
- Visual Sentiment Features: to discover which visual emotions are roused from the visualization of an image, a visual sentiment concept classification is performed based on a pre-existing ontology consisting in a collection of 3,244 visual sentiments, using the off-the-shelf convolutional network “DeepSentiBank”.
- Object Features: since image popularity is related also to the visual content of the image, we extract convolutional neural networks features from a model trained for ILSVRC 2014 challenge.
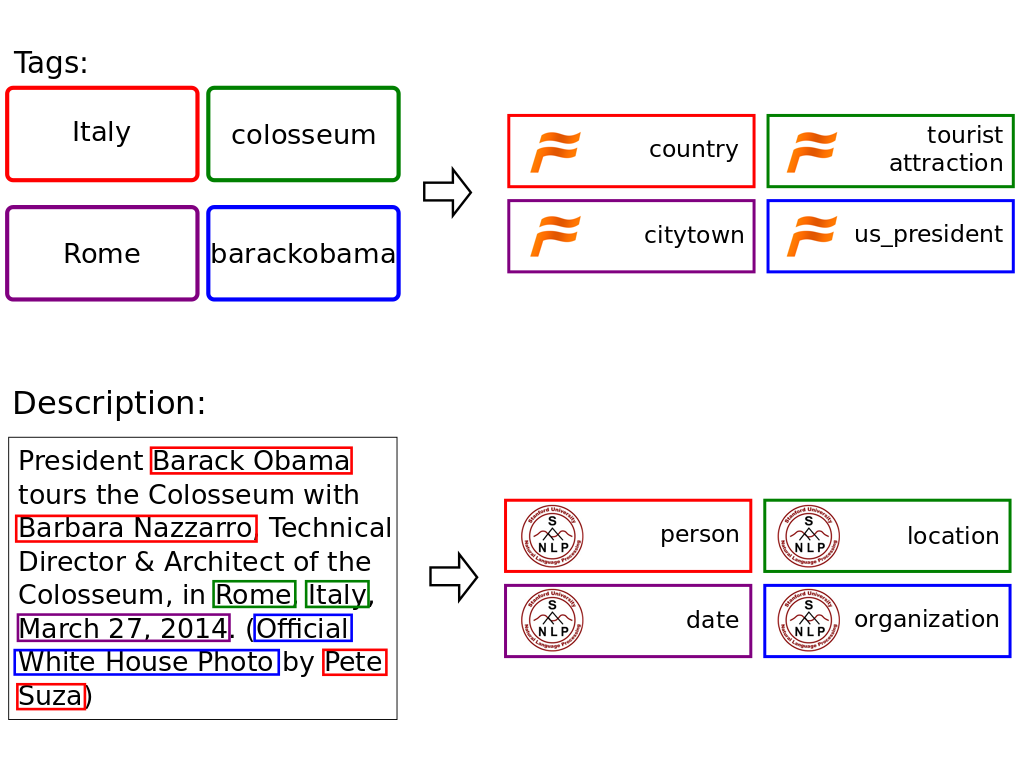
- Context Features: image context information such as tags and description contains important cues that may reflect on the number of views that an image obtains. Entities are searched for each tag using Freebase online collection, while for the description a well known CRF-based language model is adopted to perform Named Entity Recognition.