Insights
Several technological developments have spurred the sharing of images in unprecedented volumes. The first is the ease with which images can be captured in a digital format by cameras, cellphones and other wearable sensory devices. The second is the Internet that allows transfer of digital image content to anyone, anywhere in the world. Finally, and most recently, the sharing of digital imagery has reached new heights by the massive adoption of social network platforms. All of a sudden images came with tags, and tagging, commenting, and rating of any digital image has become a common habit. Despite this downpour of images and tags, the problem of searching and finding a particular image is still largely unsolved. It has instead dilated the problem with the demand of reliable and objective image tags.
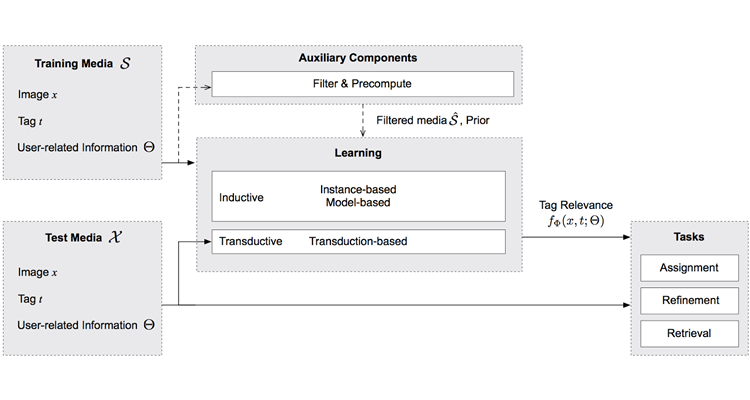
In this work we focus on challenges in content-based image retrieval in the context of social image platforms and tagging, with a unified review on three closely linked problems in the field, i.e., image tag assignment, tag refinement, and tag-based image retrieval.
Existing works in tag assignment, refinement, and retrieval vary in terms of their targeted tasks and methodology, making it non-trivial to interpret them within a unified framework. We reckon that all works rely on the key functionality of tag relevance, i.e., estimating the relevance of a specific tag with respect to the visual content of a given image. Given such a tag relevance function, one can perform tag assignment and refinement by sorting tags in light of the function, and retrieve images by sorting them accordingly. We present a taxonomy, which structures the rich literature along two dimensions, namely media and learning. The media dimension characterizes what essential information the tag relevance function exploits, while the learning dimension depicts how such information is exploited. With this taxonomy, we discuss connections and difference between the many methods, their advantages as well as limitations.
Comparative evaluation of methods and systems is imperative to appreciate progress. In spite of the growing literature in the field, there is a lack of consensus on the performance of the individual methods. This is largely due to the fact that existing works either use homemade data, which are not publicly accessible, or use selected subsets of benchmark data. Consequently we present an open-source test bed, with training sets of different sizes to evaluate methods of varied learning complexity, and three test sets contributed by various research groups. A selected set of eleven representative works, i.e., SemanticField, TagRanking, KNN, TagVote, TagProp, TagCooccur, TagCooccur+, TagFeature, RelExample, RobustPCA, TensorAnalysis, have been implemented and evaluated on the test bed for tag assignment, refinement, and/or retrieval.
We also developed a tutorial that we published in CVPR 2016 and ACM Multimedia 2015, where we also provide a practice session for hands on experience with the methods, software, and datasets. For each method a front-end pipeline is implemented, allowing users to conduct tag relevance learning from scratch, obtain tag ranks and image ranks accordingly, and report multiple performance metrics including image-centric Mean image Average Precision (MiAP), tag-centric Mean Average Precision (MAP), and Normalized Discounted Cumulative Gain (NDCG). In addition, python wrappers for C and Matlab code are given for the ease of cross-platform use.
We conclude the research with our perspective on the many challenges and opportunities ahead for the multimedia community.