Details
We identified a key missing aspect in the current literature of 4D face analysis, that is the ability of modeling complex, non-standard expressions, and transitions between them. Indeed, current models and datasets are limited to the case, where a facial expression is performed assuming a neutral-apex-neutral transition. This does not hold in the real world, where people continuously switch between one facial expression to another. These observations motivated us to generate the proposed Florence 4D dataset.
Florence 4D includes real and synthetic identities from different sources: (a) CoMA identities; (b) synthetic identities; (c) high-resolution 3D face scans of real identities.
- CoMA identities: The CoMA dataset is largely used for the analysis of dynamic facial expressions. An important characteristic of this dataset that contributed to its large use is the fixed topology, according to which all the scans have 5,023 vertices that are connected in a fixed way to form meshes with 9,976 triangular facets. The dataset includes 12 real identities (5 females and 7 males).
- Synthetic identities: On the Web, many 3D models of synthetic facial characters, either females or males, can be purchased or downloaded for free. Using these online resources, we were able to add 63 synthetic identities (33 females and 30 males) to the data, selecting those that allow editing and redistribution for non-commercial purposes. Subjects are split in three ethnic groups, Afro (16%), Asian (13%), and Caucasian (71%). Because such identities are synthetic, the resulting meshes are defect free, and perfectly symmetric, which is different from real faces. To make models more realistic, morphing solutions were applied to include face asymmetries.
- 3D real scans: We acquired 3D scans of 20 subjects (5 females and 15 males) with a 3DmD HR scanner. Subjects are mainly students and university personnel, 30 years old on average. Meshes have approximately 30k vertices. Written consents were collected for these subjects for using their 3D face scans.
Data pre-processing
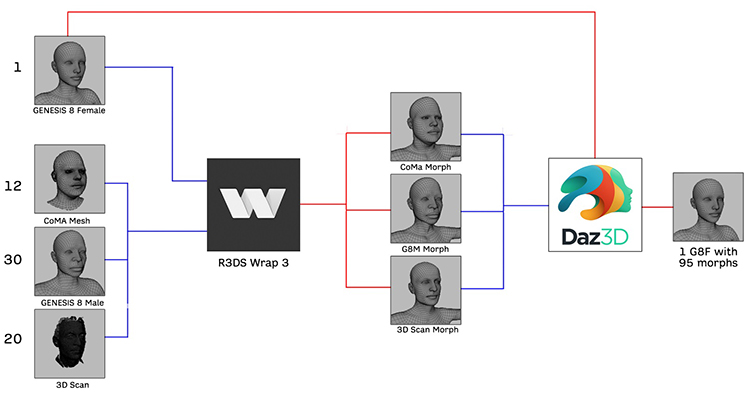
Combining the identities from the three sources indicated above, we obtained an overall number of 95 identities, 43 females and 52 males. To provide identities with the same topology as the CoMA dataset (i.e., 5,023 vertices and 9,976 triangular facets), we used a workflow that involved the joint use of the DAZ Studio and R3DS Wrap 3 software to homogenize the correspondence of the identity meshes. All identities were converted into morphs of the DAZ Studio’s Genesis 8 Female (G8-F) base mesh using the Wrap 3 software that allows one mesh to be wrapped over another by selecting corresponding points of the two meshes. The wrapped meshes were then associated with the G8-F mesh as morphs. At the end of the process, we got a G8-F mesh with 95 morphs of different identities.
After animating the facial expressions and before exporting the sequence of meshes, we restored the animated G8-F to the original topology of the CoMA dataset.
Facial expressions
With the basic Genesis 8 mesh, we also got a set of facial expressions, in the form of morphs that we used for our dataset. The number of presets was expanded by downloading free and paid packages from the DAZ Studio online shop and from other sites.
The base set included 40 different expressions. A paid package of 30 more expressions was added, obtaining a total of 70 different expressions. These expressions were classified according to the Plutchik’s wheel of emotions.
Following this organization of expressions, we generated a set of secondary expressions from the eight primary ones (for each primary expression, the number of expressions per class is indicated): anger, AR (6), fear, FR (6), sadness, SS (13), disgust, DT (9), surprise, SE (11), anticipation, AN (4), trust, TT (6), joy, JY (15).
In the dataset, we named the expressions with pairs of names representing the abbreviation of the primary emotion and the facial expression represented, e.g., JY-smile or SE-incredulous. The Genesis 8 mesh also has 70 morphs of facial expressions available, in addition to 95 identity morphs.
Creation of expression sequences
Using the above expression classification, we generated the expression sequences of each identity by iterating through the activation of the expression morphs for each identity morph.
The dataset includes two types of sequences for each identity: single expression and multiple expressions.
Single expression: For each identity, the animation of each morph expression is generated as follows:
- Frame 0 – neutral expression (morph with weight 0).
- Random frame between 10 and 50 – expression climax (morph with weight 1).
- Frame 60 – neutral expression (morph with weight 0).
The meshes in a sequence are named with the name of the expression and the number of the corresponding frame as a suffix (e.g., Smile_01)
Multiple expressions: For each identity, we created mesh sequences of transitions from a neutral expression to a first expression (expr. 1), then from this expression to a second one (expr. 2), then back from the latter to the neutral expression. Also in this case, the climax frames of the two expressions were randomized to obtain greater variability (i.e., the apex frame for each expression can occur at different times of the sequence). Summarizing, these sequences were created following this criterion:
- Frame 0 – neutral expression (morph expr. 1 weight 0).
- Random frame between 15 and 40 – morph expr. 1 with weight 1, and morph expr. 2 with weight 0
- Random frame between 50 and frame 75 – morph expr. 1 with weight 0, and morph expr. 2 with weight 1.
- Frame 90 – neutral expression (morph expr. 2 with weight 0).
Meshes in a sequence are named with the initials of the primary emotions to which the two expressions involved in the animation belong to, followed by the name of the first and second expression plus a numeric suffix for the frame (e.g., AN-AR_Confident_Glare_01).
Released data
In total, we release the 6,650 sequences that show a neutral-apex expression-neutral transition. For the sequences with neutral-expr. 1-expr. 2-neutral transition, all the possible expression combinations have been generated for a total of 198,550 sequences. We also note the neutral-expr-neutral sequences include 60 frames each, with the apex intensity for the expression occurring around frame 30; 90 frames are instead generated for the sequences with an expression-to-expression transition, with the expr. 1 apex and the expr. 2 apex occurring around frame 30 and 60, respectively.
Please, if you use the dataset cite our papers as follows:
@misc{https://doi.org/10.48550/arxiv.2210.16807,
doi = {10.48550/ARXIV.2210.16807},
url = {https://arxiv.org/abs/2210.16807},
author = {Principi, F. and Berretti, S. and Ferrari, C. and Otberdout, N. and Daoudi, M. and Del Bimbo, A.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {The Florence 4D Facial Expression Dataset},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}