Insights
Digital and mobile technologies are becoming a key factor to enhance visitors’ experiences during a museum visit, e.g. creating interactive and personalized visits. Personalization is viewed as a factor in enabling museums to change from “talking to the visitor” to “talking with the visitors”, turning a monologue to a dialogue. In this project we address the problem of creating a smart audio guide that adapts to the actions and interests of the visitor of a museum, understanding both the context of the visit and what the visitor is looking at.
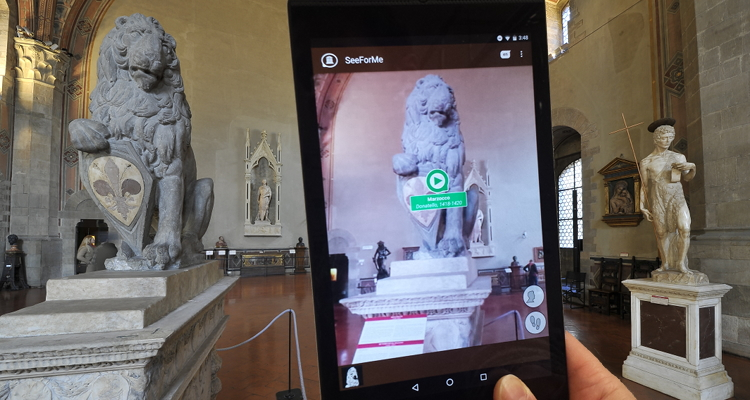
The goal of this work is to implement a real-time computer vision system that can run on wearable devices to perform object classification and artwork recognition, to improve the experience of a museum visit through the automatic detection of the behavior of users.
Object classification, sensors and voice activity detection help to understand the context of the visit, e.g. differentiating when a visitor is talking with people or his sight is occluded by other visitors, e.g. understanding if he has friends that accompany him during the visit to the museum, or he is just wandering through the museum, or if he is looking at an exhibit that interests him. Artwork recognition allows to provide multimedia insights of the observed item automatically or to create a user profile based on what and how long a user has observed artworks.
Our smart audio guide is backed by a computer vision system capable to work in real-time on a mobile device, coupled with audio and motion sensors. The system has been deployed on a NVIDIA Jetson TK1 and a NVIDIA Shield Tablet K1, and tested in the Bargello Museum of Florence.
High recognition accuracy is a requirement for the audio-guide, since mistaking an artwork for another may result in a bad user experience, e.g. this would result, at the interface level, in the audio guide presenting an artwork different from the one that is actually observed.
The system network was fine-tuned to recognize artworks and people using our dataset. Recognizing people is relevant for two reasons: first we can exploit the presence of people in the field of view to create a better understanding of context; secondly, without learning a person model, it is hard to avoid false positives on people, since artwork training data contains statues, which may picture human figures. Learning jointly a person and an artwork model, the network features can be trained to discriminate between this two classes.
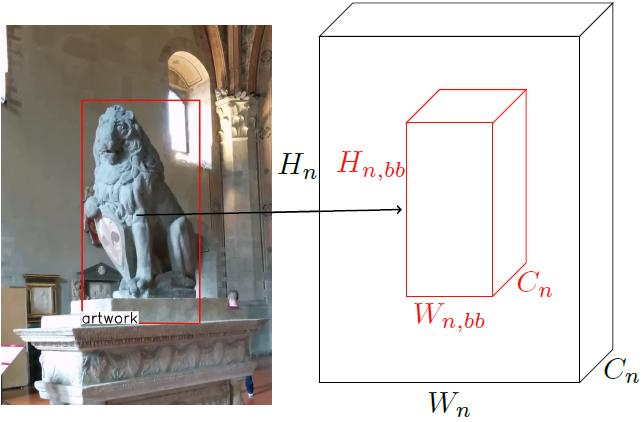
The rich features computed by the convolutional layers are exploited and re-used to compute an object descriptor for artwork retrieval. To obtain a low dimensional fixed size descriptor of a region, we apply a global max-pooling over convolutional feature activation maps, as shown in Fig. 1.
To pursue the idea of an autonomous agent that is able to understand when it is the time to engage the user and when it should be inactive, it is essential to understand the context and the status of the wearer. In addition to the observation of the same scene the user is viewing through the wearable camera, we also try to understand if the user is busy following or participating in a conversation and if he is moving around the room, both independently from the visual data.
Our audio-guide understands when the user is engaging in a conversation, if his field of view is occluded by other visitors or he is paying attention to another person or an human guide. In that event, it is reasonable to stop the audio-guide or temporarily interrupt the reproduction of any content, in order to let the user carry out his conversation.
Our system runs in real-time on a mobile device obtaining high precision artwork recognition (less then 0.3% errors on our dataset). We tested the system in the Bargello National Museum of Florence and we also a conduct a usability test using SUS questionnaires, obtaining a high score (~80/100).
A demo video is available here.


