Insights
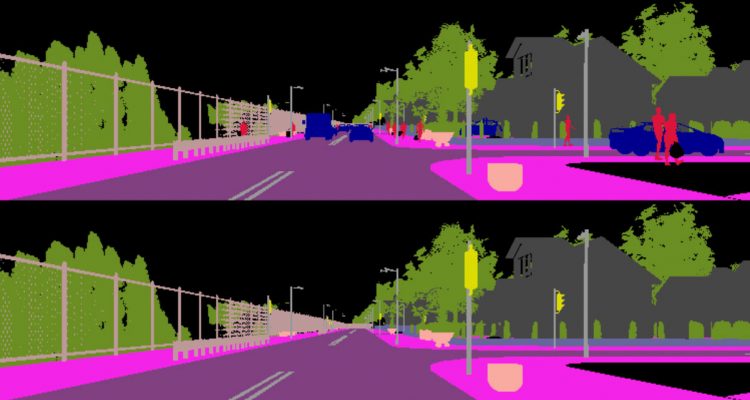
Autonomous driving is becoming a reality, yet vehicles still need to rely on complex sensor fusion to understand the scene they act in. The ability to discern static environment and dynamic entities provides a comprehension of the road layout that poses constraints to the reasoning process about moving objects. We pursue this through a GAN-based semantic segmentation inpainting model to remove all dynamic objects from the scene and focus on understanding its static components such as streets, sidewalks and buildings.
Once such a layout is recovered it is possible to derive physical constraints from the scene that can be used in all reasoning tasks regarding own and other behaviors, such as path planning and more effective obstacle avoidance. The advantages of using semantic segmentations rather than RGB are twofold: on the one hand it allows us to identify dynamic objects at a pixel-level and localize occlusion; on the other hand it directly yields a complete understanding of the image. Moreover, RGB inpainting methods still provide images which may be imprecise and of difficult interpretation. Our method instead is capable of inpainting directly the category of the restored pixels, excluding any uncertainty in the reconstruction.
In order to be able to evaluate our method we generated a synthetic dataset using CARLA, an open-source urban driving simulator built under the Unreal Engine. The sequences can be acquired as almost photo-realistic RGB videos or converted on the fly into depth or semantic segmentation maps. Thanks to this functionality we are able to programmatically generate perfectly aligned pairs of pixel-wise semantic maps with and without dynamic objects. This allows us to produce a ground truth reconstruction that would be impossible to obtain from real world images.




