Insights
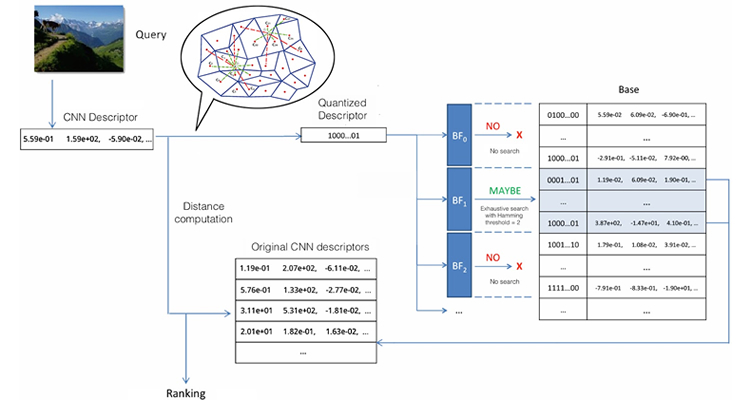
Content based image retrieval (CBIR) has been an active research topic in computer vision and multimedia in the last decades, and it is still very relevant due to the emergence of social networks and the creation of web-scale image databases. Most of the works have addressed the development of effective visual features, from engineered features like SIFT and GIST to, more recently, learned features such as CNNs. To obtain scalable CBIR systems features are typically compressed or hashed, to reduce their dimensionality and size. However, research on data structures that can efficiently index these descriptors has attracted less attention, and typically simple inverted files (e.g. implemented as hash tables) are used. We present a novel method for feature hashing, based on multiple k-means assignments, which is is unsupervised, requires a very limited codebook size and obtains a very good performance in retrieval, even with very compact hash codes. It can be applied to hash local and global visual features, either engineered (e.g. SIFT) or learned (e.g. CNNs). The proposed approach greatly reduces the need of training data and memory requirements for the quantizer, and obtains a retrieval performance similar or superior to more complex state-of-the-art approaches on standard large scale datasets. Using our quantization approach we address the problem of approximate nearest neighbor (ANN) image retrieval proposing a simple and effective data structure that can greatly reduce the need to perform any comparison between the descriptor of the query and those of the database, when the probability of a
match is very low. Considering the proverbial problem of finding a needle in a haystack, the proposed system is able to tell when the haystack probably contains no needle and thus the search can be avoided completely. To perform an immediate rejection of a search that should not return any result we store the hash code in a Bloom filter, i.e. a space efficient probabilistic data structure that is used to test the presence of an element in a set. We perform extensive experimental validation on three standard datasets, showing and how the data structure greatly improves computational cost and makes the system suitable for application to mobile devices and distributed image databases.