Insights
This work aims at overcoming the major limitations of sports analysis systems, which need one or more prerequisites such as camera calibration, training player annotations, player team/identity recognition or player tracking.
It is based on the idea that a video sequence could be better represented capturing its spatio-temporal structure by mapping visual features on relevant elements in the scene. This could be achieved employing a spectral clustering technique which groups motion trajectories following the moving and visual patterns of the elements. This is done in an unsupervised manner, dealing with the several thousands of feature extracted.
Then, we propose a cluster match kernel that allows to make correspondences among the grouped trajectories.
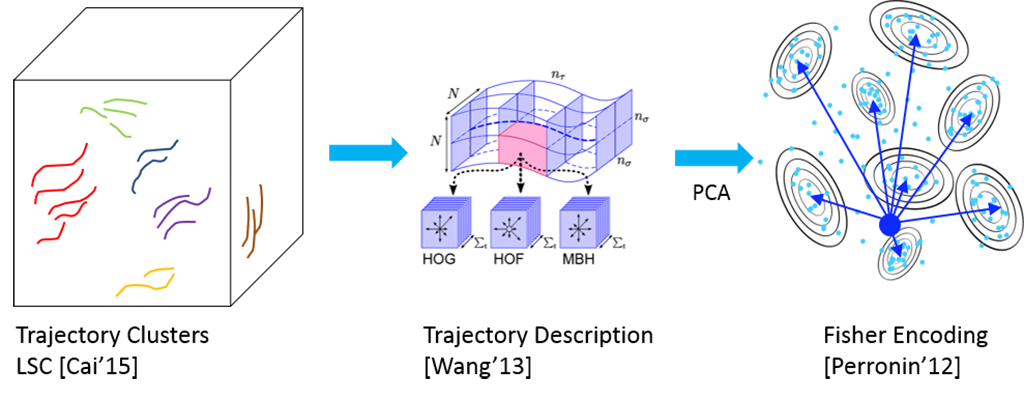
SVM is used to learn classifiers. The steps are as follows.
- Trajectory extraction. We use Improved Dense Trajectories as a feature extractor. This leads to obtain a large number of motion trajectory features to analyze. IDT Algorithm extracts both motion and appearance features (HoG, HoF, MBH).
- Trajectory clustering. To cluster trajectories, due to the large amount of features extracted by the IDT algorithm, we used Landmark Based Spectral Clustering (LSC). Spectral clustering is a relaxation of Normalized Cut algorithm that tries to exploit the connectivity of data. Spectral clustering exploits the eigenvalues of the Laplacian to obtain a better representation that allows to easily separate clusters using k-means.The main problem with big input data is computing the graph Laplacian and its factorization. We sample the input data to project the data in a smaller space, approximating the Laplacian and making eigenvectors computation more lightweight. Preselection of landmarks is performed using K-Means. Clustering is obtained taking the first k eigenvalues and eigenvectors of the approximated Laplacian, and applying K-Means using them to initialize the centroids.
- Fisher Vector Encoding. Each cluster in a video is encoded using Fisher Vectors over a Gaussian Mixture Model. Each feature vector is augmented with spatiotemporal coordinates, and Fisher Vectors are calculated with the improved algorithm (L2-normalization and power normalization are applied).
- Match kernel calculation. We then exploit the properties of Fisher Vectors to perform an exhaustive comparison between all possible pairs of clusters for each pair of videos.
- SVM Classification. The obtained kernel is used to learn an SVM Classifier which will perform the classification of the scenes.
- Feature fusion. To improve representation we show that employing multiple kernels could considerably raise classification scores. We can do this at two levels: using multiple features, which are extracted by IDT, and using different groupings (i.e. calculating the multiple match kernels with different number of clusters). Using kernels from global representation (one single cluster per video) and from clustered representation we can achieve up to ~20% improvement on the Volleyball Sport Dataset.
 Example of salient cluster mining. Notice how, in the “Setting” action, the relevant elements for recognition are the attackers and not the setter player.
Example of salient cluster mining. Notice how, in the “Setting” action, the relevant elements for recognition are the attackers and not the setter player.Besides action classification, this framework is capable of performing a salient clusters mining, which could also bring to a localization of the action in the scene.
We performed some preliminary tests on the capability of this system to locate most relevant clusters in a scene, and observed that the classifier distinguishes some classes basing on some elements which are different from the subject who is actually performing the action.