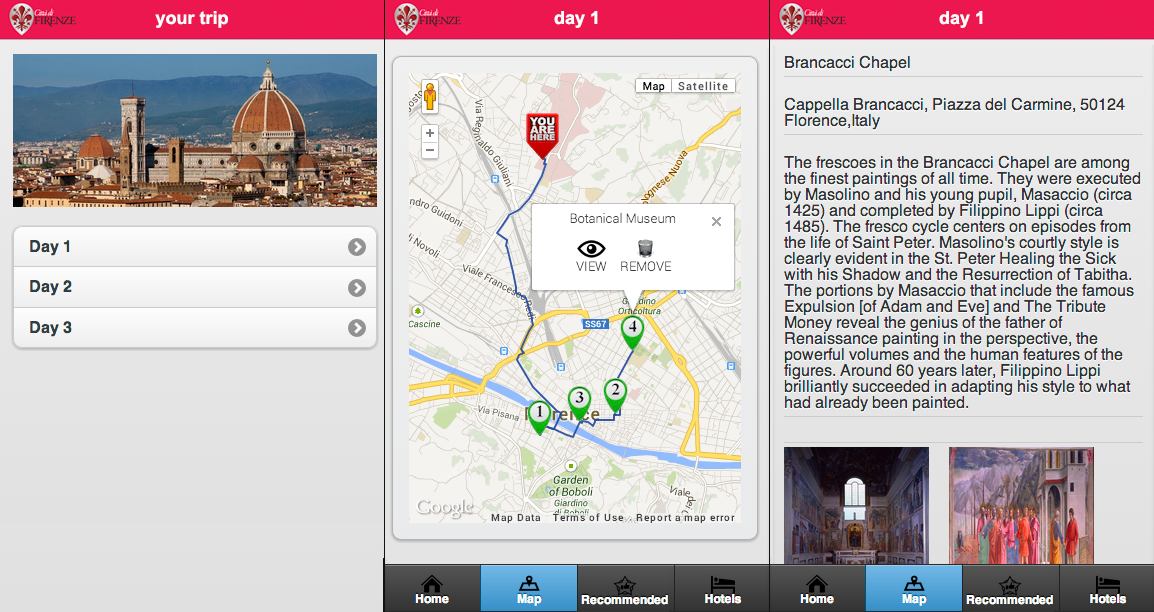
Prototype of a web framework for the definition and modification of a personalized visit in the city of Florence accessible through different devices. In particular the system exploits a wall mounted touchscreen in a visitor center for the early definition of a city visit plan transferrable on a mobile phone. Once the route plan is transferred, the mobile application allows updates and changes of the plan as well as to access geolocalized information of each Point Of Interest during the visit in the city. An application server platform and a network infrastructure permits to record user activities as well as search and retrieve personalized data.
People Interacting with the touchscreen
The prototype system is currently under test at the Media Integration and Communication Center of the University of Florence and is developed in a joint project between the University of Florence and the Municipality of Florence. It will be part of the newly started project Social Museum and Smart Tourism that has been funded under the Cluster program of MIUR. It is expected to be in operation by January 1st 2014.
VIVIT is a three-years project led by Media Integration and Communication Center (MICC) and Accademia della Crusca, funded on government FIRB funding. As a part of this project, the VIVIT web portal has been developed by MICC in order to give visibility to culture-related contents that may appeal to second and third generation Italians living abroad.
Vivit web portal
The main aim of the VIVIT web portal is to provide people of italian origins with quality content related to the history of the nation and that of the language, together with learning materials for self-assessment and improvement of the viewer’s language proficiency.
The development of the VIVIT web portal has officially started in 2010, when the information architecture and content organization were first discussed. The VIVIT project stated that the web portal should give users and potential teachers ways to interact with each other and to produce and reorganize contents to be shown online to language and culture learners. Given these premises, it was decided to make use of a CMS (Content Management System), the possibility of user roles definition and interaction being part of its nature.
VIVIT is being developed on Drupal. Free and open-source PHP-based software, Drupal has come a long way over recent years in features development and is now considered one of the best CMS systems together with the well-known WordPress and Joomla. A large amount of user-contributed plugins (modules, in Drupal terms) and layout themes is available, since the development process itself is relatively simple and widely documented.
At this time, the architecture of the VIVIT portal is mostly complete: users may browse content, comment on it, bookmark pages and reorganize them from inside the platform (users with the role of teachers may also share these self-created content units with other users, to create their own learning path through the contents of the web portal); audio and video resources are available as well as learning materials that allow user interaction granted by the use of a custom jQuery plugin developed internally at MICC.
It is also possible, for users with enough rights, to semantically process and annotate (that is, assign resources that describe the content) texts inside the portal by using the named entities and topic extraction servlet Homer, also developed at MICC: the tagging possibility is part of Drupal core modules, while the text analysis feature is a combination of the contributed tagging module and a custom module written specifically for the VIVIT portal. The Homer servlet is a Java application based on GATE, a toolkit for a broad range of NLP (Natural Language Processing) tasks.
LIT. Lexicon of Italian Television search engine
The VIVIT web portal gives access to additional resources related to the same cultural field: in particular LIT (Lexicon of Italian Television) and LIR (Lexicon of Italian Radio). The former, LIT, is a Java search engine that uses Lucene in order to index about 160 video excerpts from Italian TV programs of about 30 minutes each, chosen from the RAI video archive. LIT also offers a backend system where it is possible to stream the video sequences, synchronize the transcriptions with the audio-video sources, annotate the materials by means of customized taxonomies and furthermore add specific metadata. The latter, LIR, is a similar system that relies on an audio archive composed of radio segments from several Italian sources. Linguists are currently using LIT and LIR for computational linguistics based research.
The explosion of digital data in recent times, in its varied forms and formats (MPEG4 image, Flash video, WAV audio, etc.), has necessitated the creation of effective tools to organise, manage and link digital assets, in order to maximise accessibility and reduce cost issues for everyone concerned, from content managers to online content consumers.
euTV video annotation and transcription web component
On a larger scale, isolated information repositories developed by content owners and technology providers can be connected, unleashing opportunities for innovative user services and creating new business models, in the vein of on-demand, online, or mobile TV ventures.
The euTV project stems from above conditions and potentialities, to connect publicly available multimedia information streams under a unifying framework, which additionally allows publishers of audio-visual content to monetise their products and services. The backbone of euTV is a scalable audio-visual analysis and indexing system that allows detection and tracking of vast amounts of multimedia content based on Topics of Interest (TOI) corresponding to a user’s profile and employed search terms. The front-end is a portal that displays syndicated content, allowing users to perform searches, refine queries, and produce faceted presentation of results.
euTV logo
The three main content domains will be (a) news, (b) sports, and (c) documentaries. In the existing market of media monitoring and clipping, euTV distinguishes itself by simultaneously analysing multiple information streams (text, speech, audio, image, video) instead of a single one and tracking TOI in real time. This provides the user with a more robust identification of their TOI and greater insights into how the information is spread.
A technology transfer project for the Regione Toscana in order to provide a solution to predict the effects of geothermal power both in the same basin and the surrounding environment in some areas of Tuscany.
Geotherm viewer data visualization
A web application in a GIS environment is designed and developed in order to visualize and query simulation data and their scenarios stored in a geospatial database.
The MAC-GEO project aims to give the Regione Toscana some simulation tools to predict the effects of geothermal power both in the same basin and the surrounding environment.
The project was funded by Regione Toscana CIPE funds, following the announcement Framework Programme Agreement Research and technology transfer for the production system – Supplementary Agreement III.
The project started in September 2008 and lasts two years.
MICC research staff designed and developed the Geotherm Viewer, a web application in a GIS environment for viewing and querying simulation data and their scenarios stored in geospatial database.
The system was designed for users who need to quickly view the results of the generated simulations in order to assess which groups of data for later analysis and deepen the effects of geothermal both in the same basin and the surrounding environment. In addition, the user-interface provides a set of interactive features for geographic data visualization, data from web map services and information generated by Google Maps.
The Geotherm Viewer has been developed with open source technologies.
LIT (Lexicon of the Italian Television) is a project conceived by the Accademia della Crusca, the leading research institution on the Italian language, in collaboration with CLIEO (Center for theoretical and historical Linguistics: Italian, European and Oriental languages), with the aim of studying frequencies of the Italian lexicon used in television content and targets the specific sector of web applications for linguistic research. The corpus of transcriptions is constituted approximately by 170 hours of random television recordings transmitted by the national broadcaster RAI (Italian Radio Television) during the year 2006.
LIT: Lexicon of the Italian Television
The principal outcome of the project is the design and implementation of an interactive system which combines a web-based video transcription and annotation tool, a full featured search engine, and a web application, integrated with video streaming, for data visualization and text-video syncing.
The project presents two different interfaces: a search engine, based on classical textual input forms, and another multimedia interface, used both for data visualization and annotation. Annotation functionalities are activated after user’s authentication. The systems relies on a web application backend which has to handle the transcriptions and provide the necessary indexing and search functions.
The browsing interface shows the video collection present in the model. Users can select a video and play it immediately, and read the associated metadata and speech transcription in sync. Each record in the list of videos provides a link to the raw annotation in XML-TEI format, a standard developed by the TEI: Text Encoding Initiative Consortium. The annotation can be opened directly inside the browser and saved on the local systems. Subtitles are displayed at the bottom of the video while segments in the transcription area are automatically highlighted during playback and metadata are updated accordingly. When the text-to-speech alignment is completed through annotation activities, users can select a unit of text inside the transcription area and the video cue-point is aligned accordingly; on the contrary, scrolling the trigger on the annotated video segment highlights the corresponding segment of text.
The annotation interface is accessed by transcriptionists after authentication, and allows to associate the transcription to the corresponding sequences of video. Annotators can set the cue points of speech on the video sequences using the tools provided by the graphic user interface and assign them an annotation without having prior knowledge of the format used. The tool provides functionalities for the definition of metadata at different levels, or multiple “layers”: features can be assigned to the document as a whole, to individual transmissions, to speakers in the transmissions and to each single segment of the transcription.
The search interface is based on standard text input fields. It provides a JSP frontend to the search functions defined for the Java engine and uses the Lucene query syntax for the identification of HTML elements. The interfaces recalls a common ‘advanced search’ form, providing all the boolean combinations usually present in search engines and, for this reason, making users comfortable with basic features. Notably, some uncommon features appears among other fields, such as:
the ‘free sequence’ field, with option for defining it exact, ordered or unordered;
the ‘distance’ parameter, where free sequences can appear within specified ranges inside a single utterance;
the ‘date range’ parameter.
Advanced search features are shown inside dedicated panels which can be expanded if necessary. These panels give all the options for specifying the constraints of a query, as defined for the XML-TEI custom fields used in LIT. The extended parameters allow to:
set the case sensitiveness of a query;
perform a word root expansion of jolly characters present in the query;
set the constraint for specific categories defined in the taxonomy;
select specific parameters for utterances, such as type of speech (improvisation, programmed, executed), speech technique (on scene, voice-over), type of communication (monologue, dialogue), speaker gender and type (professional, non professional).
The system contains 168 hours of RAI (Italian Radio Television) broadcasts, aired during the year 2006. The annotation work was done by researchers of the Accademia della Crusca while LIT was under development, in late 2009. The database has approximately 20.000 utterances stored and using Lucene for search and retrieval does not raise any performance issue.
The system is currently under deployment as a module of the larger national research funding FIRB 2009 VIVIT (Fondo di Investimento per la Ricerca di Base, Vivi l’Italiano), which will integrate the tools and the obtained annotations within a semantic web infrastructure.
The Mediateca Medicea is a digital archive relating to Palazzo Medici Riccardi, one of the most important buildings in Florence, which now belongs to the Provincial Authority and houses the administrative offices. The Mediateca Medicea is designed in particular for academics and experts in the fields of art, history, the humanities, photography and the conservation of the cultural heritage, but also for students or scholars following up specific strands of research.
Mediateca di Palazzo Medici Riccardi
The database is made up of different types of interrelated materials: texts, images, graphic reconstructions, and anything else which may contribute to a knowledge of the building in historic, architectural, artistic and cultural terms. The Mediateca extends and elaborates the subjects dealt with in the website www.palazzo-medici.it, with which it is connected.
The project has been organised and carried out by the Florence Provincial Authority, in collaboration with the Media Integration and Communication Center of the University of Florence, through the co-operation of a group of different professional figures (art historians, computer experts, photographers…) who have found a stimulating point of encounter in an innovative and flexible documentation tool that is at once exhaustive and easy to use.
The site is offered in the form of an in-progress database that will be extended, modified and updated in real time.