Mnemosyne is a research project carried out by the Media Integration and Communication Center – MICC, University of Florence along with Thales Italy SpA. and funded by the Tuscany region. The goal of the project is the study and experimentation of smart environments which adopts natural interaction paradigms for the promotion of artistic and cultural heritage by the analysis of visitors behaviors and activities.

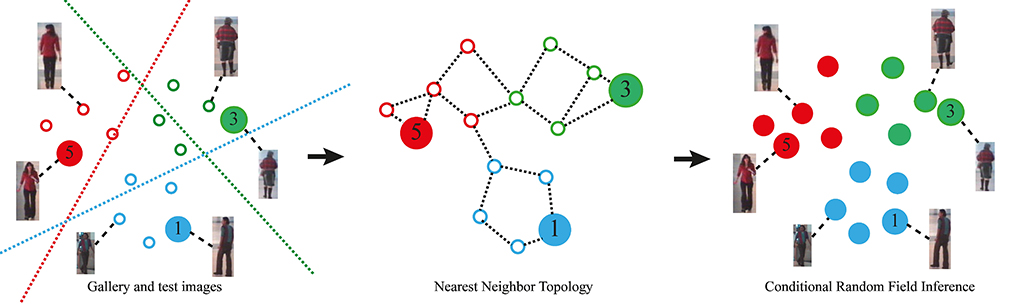
The idea behind this project is to use techniques derived from videosurveillance to design an automatic profiling system capable of understanding the personal interest of each visitor. The computer vision system monitors and analyzes the movements and behaviors of visitors in the museum (through the use of fixed cameras) in order to extract a profile of interests for each visitor.
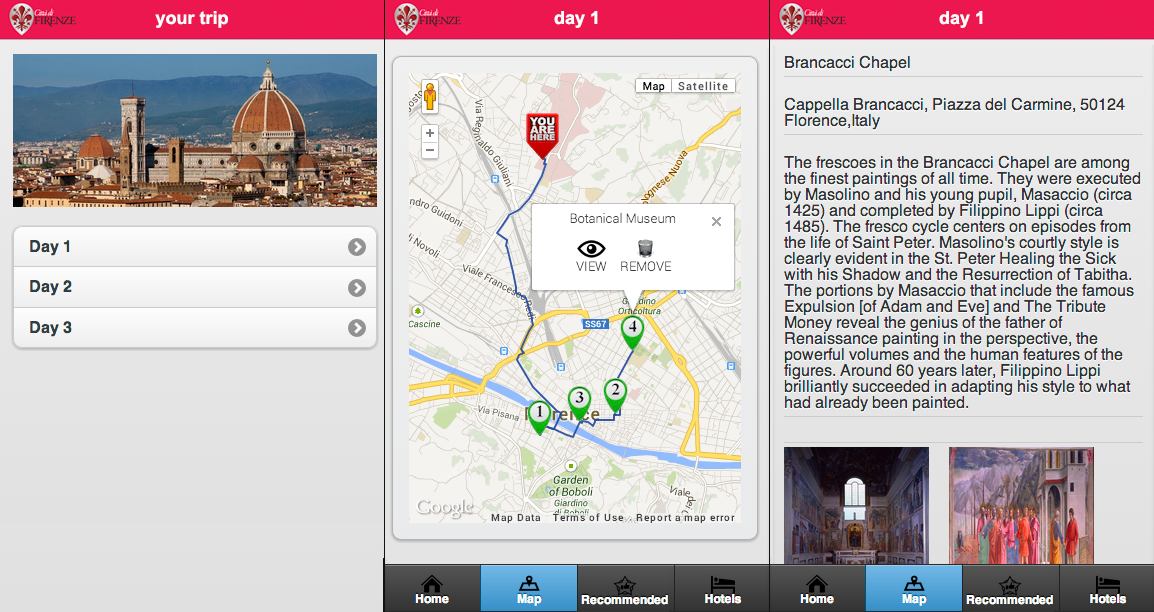
This profile of interest is then used to personalize the delivery of in-depth multimedia content enabling an augmented museum experience. Visitors interact with the multimedia content through a large interactive table installed inside the museum. The project also includes the integration of mobile devices (such as smartphones or tablets) offering a take-away summary of the visitor experience and suggesting possible theme-related paths in the collection of the museum or in other places of the city.
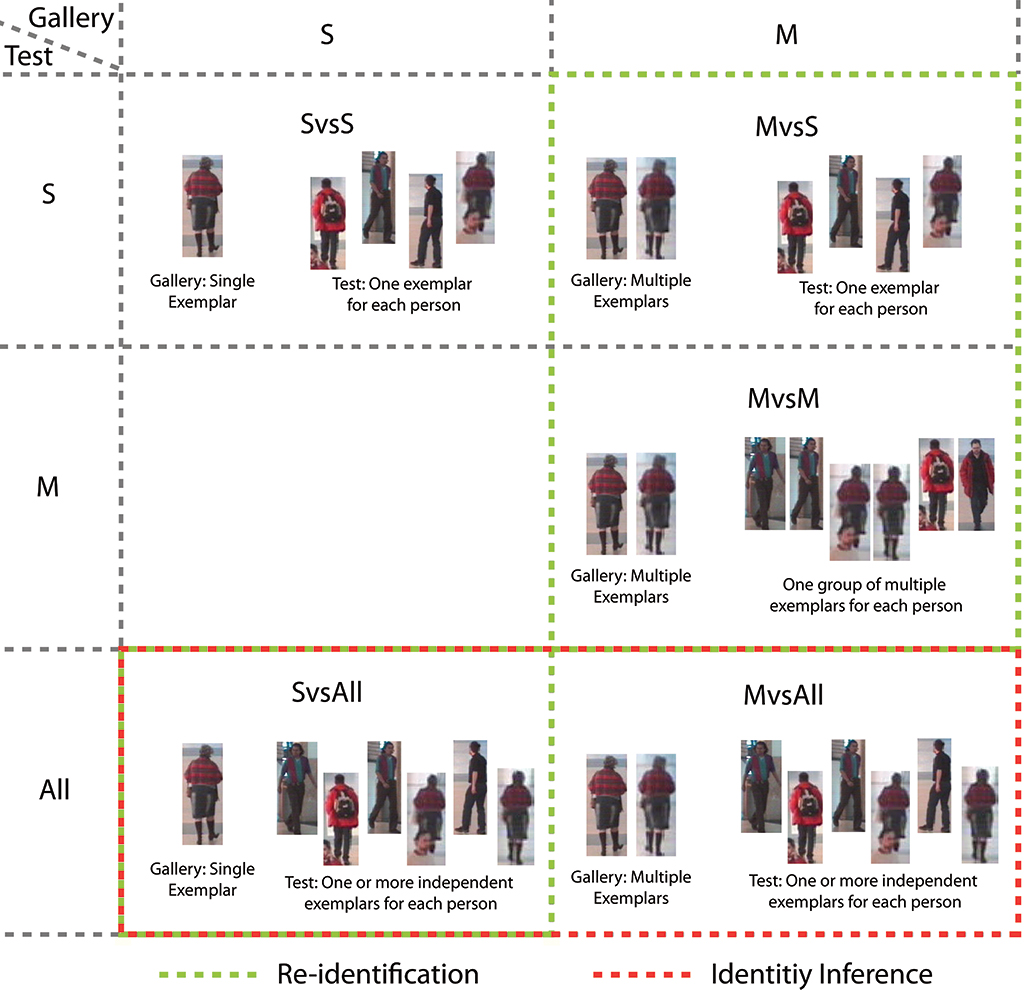
The system operates in a total respect of the privacy of the visitor: the cameras and the vision system only capture information on the appearance of the visitor such as color and texture of the clothes. The appearance of the visitor is encoded into a feature vector that captures its most distinctive elements. The feature vectors are then compared with each other to re-identify each visitor.
Mnemosyne is the first installation in a museum context of a computer vision system to provide visitors with personalized information on their individual interests. It is innovative because the visitor is not required to wear or carry special devices, or to take any action in front of the artworks of interest. The system will be installed, on a trial basis until June 2015, in the National Museum of the Bargello in the Hall of Donatello, in collaboration with the management of the Museum itself.
The project required the work of six researchers (Svebor Karaman, Lea Landucci, Andrea Ferracani, Daniele Pezzatini, Federico Bartoli and Andrew D. Bagdanov) for four years. The installation is the first realization of the Competence Centre Regional NEMECH New Media for Cultural Heritage, made up of the Region of Tuscany and Florence University with the support of the City of Florence.