Insights
The problem of object detection has assumed a central role in computer vision. The ultimate goal in many real case scenarios is to automatically understand what is happening in a given context. What is required is a comprehension of the scene in a semantic sense and therefore classical approaches to the problem of object detection may no longer be sufficient.
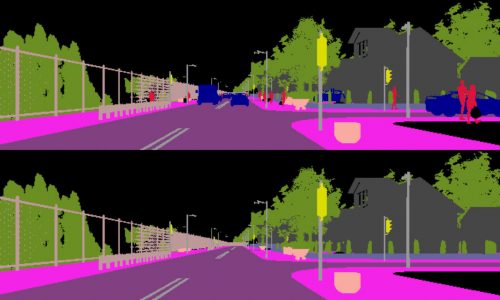
In addition to the classical output of an object detection algorithm, i.e. localization information and a categorical label, it would be useful to automatically produce segmentation masks, shape details, tridimensional geometry and so forth.
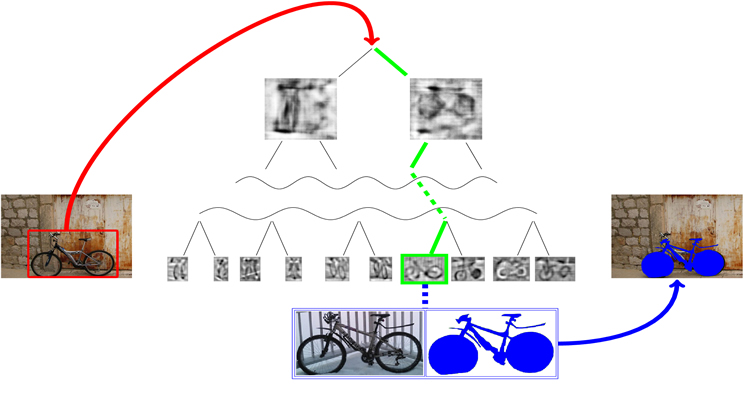
Using ensembles of Exemplar-SVMs as object detectors, where a SVM is trained for each positive example in the training set, this kind of semantic annotation can be easily added simply transferring any available annotation from training samples to detected objects. The main drawback of this method is that the evaluation of an ensemble of Exemplar-SVMs is very slow since hundreds or thousands of separate classifiers have to be tested for each detection.
We show that a data structure such as a tree is capable of approximating the output of a given ensemble of Exemplar-SVMs speeding up the process of evaluation. The goal is to introduce a logarithmic factor instead of a linear one with regard to the number of Exemplar-SVMs that need to be evaluated.
This taxonomy-like structure must provide results comparable to the baseline given by the ensemble, both in terms of detection accuracy and in terms of label transfer capability. In case of failure, the produced output (intended as transferred semantic annotation) must be similar to the one given by the ensemble.
The taxonomy is built by clustering Exemplar-SVMs hierarchically and is evaluated by extracting patches from test images in a sliding window fashion. The complexity of the method is reduced from O(NM) to O(log(N)W), where N is the number of Exemplar-SVMs and M the number of extracted windows.
Early rejection thresholds are also learnt for each node in the taxonomy in order to discard unpromising windows at the higher levels of the tree. This can drastically reduce the number of comparisons for each image, leading to a considerable speed-up.