Person re-identification is a standard component of multi-camera surveillance systems. Particularly in scenarios in which the longterm behaviour of persons must be characterized, accurate re-identification is essential. In realistic, wide-area surveillance scenarios such as airports, metro and train stations, re-identification systems should be capable of robustly associating a unique identity with hundreds, if not thousands, of individual observations collected from a distributed network of very many sensors.
Traditionally, re-identification scenarios are defined in terms of a set of gallery images of a number of known individuals and a set of test images to be re-identified. For each test image or group of test images of an unknown person, the goal of re-identification is to return a ranked list of individuals from the gallery.
Configurations of the re-identification problem are generally classified according to how much group structure is available in the gallery and test image sets. In a single-shot image set there is no grouping information available. Though there might be multiple images of an individual, there is no knowledge of which images correspond to that person. In a multi-shot image set, on the other hand, there is explicit grouping information available. That is, it is known which images correspond to the same individual.
While such characterizations of re-identification scenarios are useful for establishing benchmarks and standardized datasets for experimentation on the discriminative power of descriptors for person re-identification, they are not particularly realistic with respect to many real-world application scenarios. In video surveillance scenarios, it is more common to have many unlabelled test images to re-identify and only a few gallery images available.
Another unrealistic aspect of traditional person re-identification is its formulation as a retrieval problem. In most video surveillance applications, the accuracy of re-identification at Rank-1 is the most critical metric and higher ranks are of much less interest.
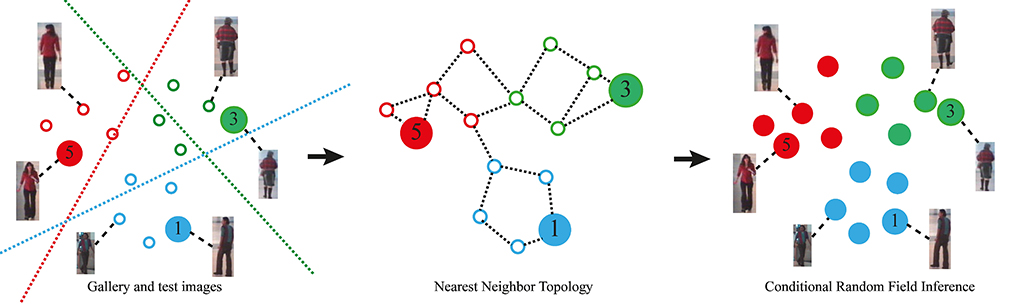
Based on these observations, we have developed a generalization of person re-identification which we call identity inference. The identity inference formulation is expressive enough to represent existing single- and multi-shot scenarios, while at the same time also modelling a larger class of problems not discussed in the literature.
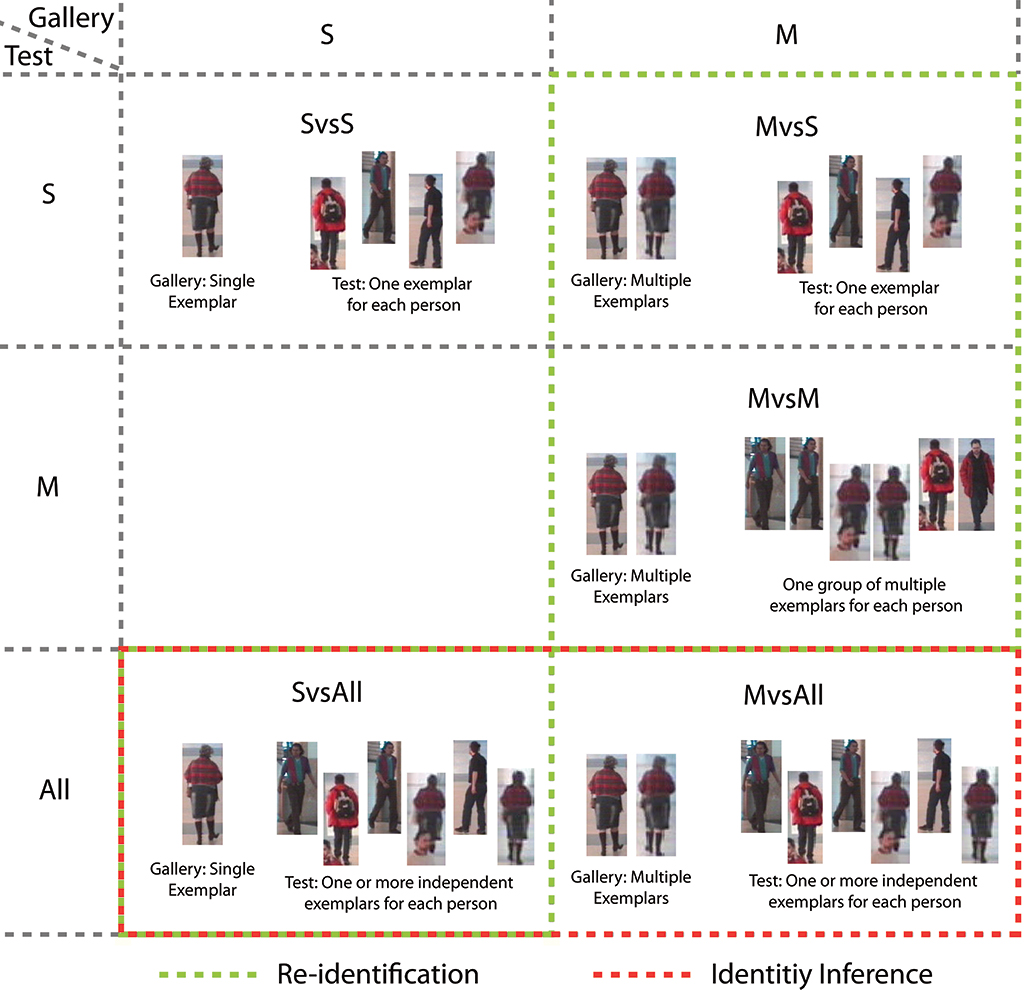
In particular, we demonstrate how identity inference models problems where only a few labelled examples are available, but where identities must be inferred for very many unlabelled images. In addition to describing identity inference problems, our formalism is also useful for precisely specifying the various multi- and single-shot re-identification modalities in the literature.
We show how a Conditional Random Field (CRF) can then be used to efficiently and accurately solve a broad range of identity inference problems, including existing person re-identification scenarios as well as more difficult tasks involving very many test images. The key aspect of our approach is to constraints the identity labelling process through local similarity constraints of all available images.


